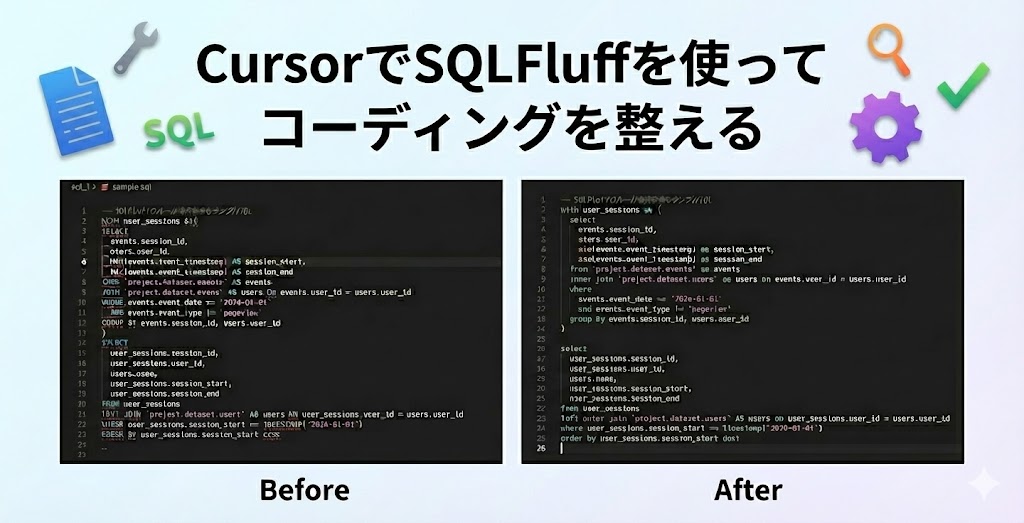
SQLのコーディングを整えるSQLFluffの導入方法を解説
はじめに
データ分析の現場では、複数のメンバーがSQLを書くため、コーディングスタイルがバラバラになりがち。スタイルが統一されていないと、ミスが出やすかったり、レビューが非効率になったり、後から見返したときによく分からなかったり、といった問題が発生します。
このような問題を解決するのが「SQLFluff」というSQL Linter(リンター)です。SQL Linterとは、SQLコードの品質やスタイルを自動でチェック・整形するツールのこと。特に「Cursor」というエディタでSQLFluffを使えば、リアルタイムにルール違反を指摘してくれ、ワンクリックで自動修正も可能!
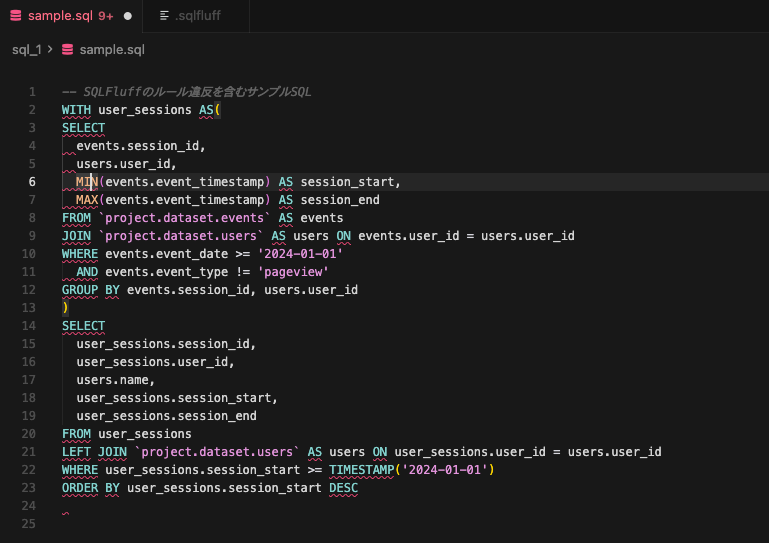
この記事では、BigQuery向けのSQLFluff設定方法と、Cursorでの使い方を分かりやすく紹介していきます。設定ファイル(.sqlfluff)を共有すれば、組織全体で同じルールを適用できるため、コーディングスタイルの統一が簡単に実現できます。
SQLFluffとは
SQLFluffは、SQL Linter(リンター)の一種です。Linterとは、コードの品質やスタイルを自動でチェックするツールのことで、プログラミング言語ごとに様々なLinterが存在します(例:JavaScriptのESLint、PythonのPylintなど)。SQLFluffは、そのSQL版。
- ルール違反の自動検出:大文字小文字の不統一、インデントの誤りなどを自動で検出
- 自動整形:ワンクリックで、ルールに沿って自動でコードを整形
- カスタマイズ可能:組織やプロジェクトごとにルールを設定可能
Cursorの拡張機能を使えば、SQLを書いているときに自動でルール違反を波線で表示し、右クリックで自動修正ができます。パッと使えるのでとても便利。
SQLFluffの設定方法
ターミナルからSQLFluffをインストール
まず、ターミナルからSQLFluffをインストールしましょう。macOSの場合は、Homebrewを使ってbrew install sqlfluffのコマンドを実行するだけです。
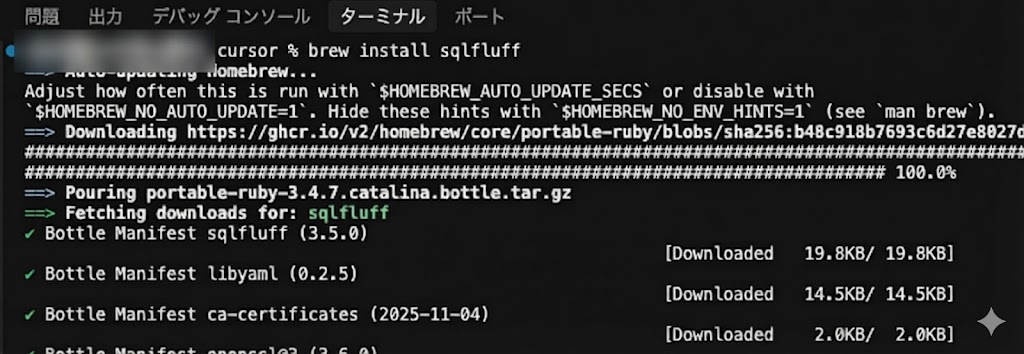
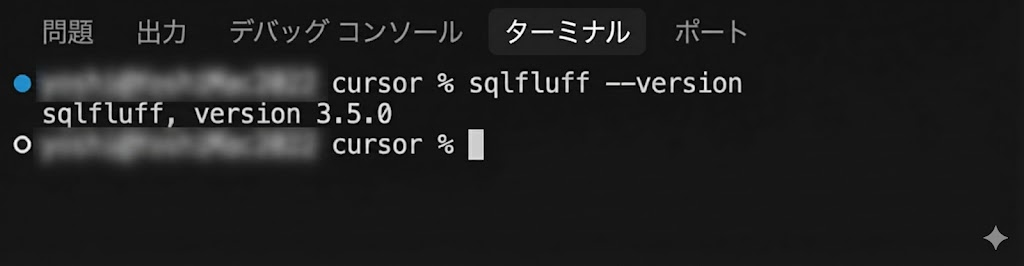
sqlfluff --versionでインストールできていることを確認。
Cursor拡張機能のインストール
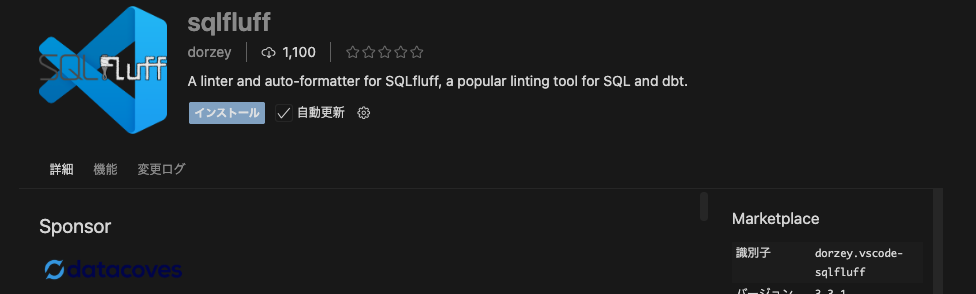
次に、CursorでSQLFluff拡張機能をインストールします。Cursorの拡張機能マーケットプレイスを開いて、sqlfluffで検索して、「dorzey」が公開している「sqlfluff」拡張機能をインストールします。
設定ファイルの配置
最後に、SQLFluffの設定ファイル(.sqlfluff)を、SQLファイルがあるディレクトリの上位ディレクトリに配置します。SQLFluffは再帰的に上位ディレクトリを検索するため、プロジェクトのルートディレクトリに配置すれば、すべてのSQLファイルに適用されます。
project/
├── .sqlfluff ← ここに配置
└── sql/
├── query1.sql
└── query2.sql自分が利用している.sqlfluffの中身は↓です。Bigquery用で、特にこだわりない方はそのまま使ってください。詳細は後で解説します。この設定ファイルを共有するだけで、チーム全体で同じルールを適用できます。
[sqlfluff]
# BigQuery用の方言設定
dialect = bigquery
# 行の長さ制限(120文字)
max_line_length = 120
# ファイルサイズ制限を無効化(0に設定)
large_file_skip_byte_limit = 0
# テンプレーターなし(純粋なSQLのみをLint)
# templaterは設定しない(デフォルトのrawを使用)
# 除外するルール
# BigQueryの特性に合わせて、以下のルールを除外
exclude_rules =
# エイリアス使用を禁止するルール(BigQueryではエイリアス必須)
aliasing.forbid,
# SELECT *を使いたい場面が多いため除外
ambiguous.column_count,
# * EXCEPT構文を使うため除外
structure.column_order
# インデント設定
[sqlfluff:indentation]
# インデント幅は2スペース
tab_space_size = 2
# 大文字小文字の統一設定(すべて小文字)
[sqlfluff:rules:capitalisation.keywords]
# SQLキーワードは小文字で統一
capitalisation_policy = lower
[sqlfluff:rules:capitalisation.identifiers]
# 識別子(テーブル名、カラム名)は小文字で統一
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.functions]
# 関数名は小文字で統一
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.types]
# データ型名は小文字で統一
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.literals]
# リテラル値(文字列、数値)は小文字で統一
extended_capitalisation_policy = lower
# 長い行の扱い
[sqlfluff:rules:layout.long_lines]
# コメント行は長さ制限から除外
ignore_comment_lines = True
# カンマの配置スタイル
[sqlfluff:rules:layout.commas]
# カンマを行末に配置(トレーリングカンマ)
trailing_comma = True
# 末尾カンマ
[sqlfluff:rules:convention.select_trailing_comma]
# 末尾カンマを必須とする
select_trailing_comma = require
# エイリアスのASキーワード
[sqlfluff:rules:aliasing.table]
# テーブルエイリアスにASキーワードを必須とする
require_as = True
[sqlfluff:rules:aliasing.column]
# カラムエイリアスにASキーワードを必須とする
require_as = True
[sqlfluff:rules:aliasing.expression]
# 式エイリアスにASキーワードを必須とする
require_as = True
# CTE vs サブクエリ
[sqlfluff:rules:structure.subquery]
# JOIN句とFROM句の両方でサブクエリを禁止(CTEを推奨)
forbid_subquery_in = both
# USING句の使用
[sqlfluff:rules:structure.using]
# USING句の使用を禁止し、ON句を推奨
forbid_using = True
# カラム参照の修飾
[sqlfluff:rules:references.qualification]
# カラム参照にテーブル名やエイリアスを必須とする
require_qualification = True
# 不等号の記法
[sqlfluff:rules:convention.not_equal]
# SQL標準の不等号`<>`を推奨
preferred_not_equal_operator = <>
# COALESCE関数の使用
[sqlfluff:rules:convention.coalesce]
# COALESCE関数の使用を推奨
prefer_coalesce = True
# 予約語の使用
[sqlfluff:rules:references.keywords]
# 予約語の使用を検出
forbid_keywords = True
# JOIN条件の順序
[sqlfluff:rules:structure.join_condition_order]
# 先に参照されたテーブルを先に記述
preferred_first_table_in_join_clause = earlier
# 未使用のJOIN
[sqlfluff:rules:structure.unused_join]
# 未使用のJOINを検出
forbid_unused_join = True
# JOINタイプの明示
[sqlfluff:rules:ambiguous.join]
# INNERもOUTERも明示することを推奨
fully_qualify_join_types = both
使い方
使い方は簡単で、SQLファイルを開くと、SQLFluffが自動でルール違反を検出し、赤の波線が表示されます。

ルール違反を修正するには、SQLファイル内で右クリックして、「ドキュメントのフォーマット」をクリック。
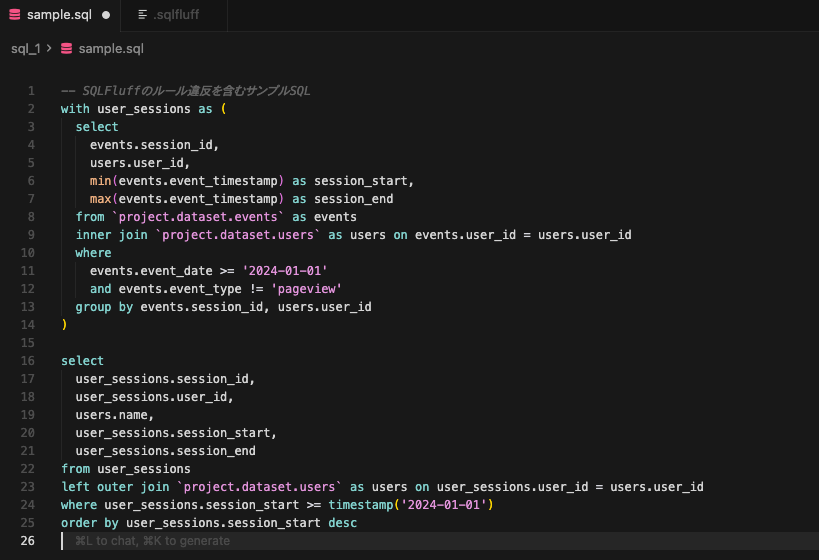
SQLFluffが自動でコードを整形し、ルール違反を修正してくれます。出力結果(データ)は変更されず、コードのスタイルだけが修正されるので安心。ここが生成AIを使ったコーディングの修正との大きな違いですね。
BigQuery向け設定ファイル
最後に、自分が利用しているBigQuery用のSQLFluffの設定を紹介します。
| 項目 | 該当ルール / 設定キー | 設定内容 | 理由 |
| 1. 大文字小文字の統一方針 | CP01〜CP05: capitalisation.* | すべて小文字統一 | dbt Labsのスタイルガイドでも採用されており、モダンな分析環境では標準的。 |
| 2. インデント | LT02: layout.indent | 2スペース | BigQueryのWeb UIでの可読性を考慮。 |
| 3. 行の長さ制限 | LT01: layout.long_lines | 120文字 | BigQueryの長い識別子を考慮。 |
| 4. コメント行の扱い | ignore_comment_lines | 長さ制限から除外 | コメントは可読性に直接影響しないため、長さ制限の対象外とする。 |
| 5. 引用符のスタイル | (設定なし) | シングルクォート | BigQueryの標準に合わせて、文字列リテラルはシングルクォートで統一。 |
| 6. カンマの配置スタイル | LT04: layout.commas | トレーリングカンマ | 行末カンマ。BigQueryでは末尾カンマが構文エラーにならず、修正時の差分も最小化できるため。 |
| 7. 末尾カンマ | CV03: trailing_comma | 必須 (require) | Gitの差分を考慮(ただし、カンマの位置がleadingの場合は不要)。 |
| 8. エイリアスのASキーワード | AL01, AL02, AL03 | 有効化 | 明示的なエイリアス定義により可読性を重視。 |
| 9. エイリアス禁止ルール | AL07, L031 | 除外 (無効化) | BigQueryの特性上、計算式等でのエイリアスの使用は必須のため。 |
| 10. CTE vs サブクエリ | ST01: structure.subquery | 有効化 (both) | BigQueryはCTEをサポートしているため、サブクエリよりCTEを推奨。 |
| 11. USING句の使用 | ST03: structure.using | 有効化 (禁止) | USING句の使用を禁止し、より明示的なON句を推奨。 |
| 12. カラム参照の修飾 | RF01: qualification | 有効化 | 複数テーブルのJOIN時にどのテーブルのカラムかを明確にするため。 |
| 13. 不等号の記法 | CV01: convention.not_equal | <> を推奨 | SQL標準(ANSI SQL)に準拠。 |
| 14. COALESCE関数の使用 | CV02: convention.coalesce | 有効化 | IFNULL等よりも標準的であり、可読性を重視。 |
| 15. 予約語の使用 | RF02: references.keywords | 有効化 | 予約語を識別子として使うことによるエラーを防ぐため。 |
| 16. JOIN条件の順序 | ST05: join_condition_order | 有効化 (earlier) | 先に参照されたテーブルを左辺に記述し、読みの流れを統一する。 |
| 17. 未使用のJOIN | ST07: structure.unused_join | 有効化 | 不要な結合を削除し、クエリパフォーマンスを向上させる。 |
| 18. JOINタイプの明示 | fully_qualify_join_types | 明示 (both) | INNER も OUTER も省略せず書き、意図を明確にする。 |
| 19. カラム数不一致 | AM04, L044 | 除外 (無効化) | BigQueryでは SELECT * を使いたい場面(データ探索等)が多いため。 |
| 20. カラム順序 | ST02, L034 | 除外 (無効化) | BigQueryの * EXCEPT 構文と競合するため除外。 |
| 21. テンプレートエンジン | templater | raw (なし) | dbtやJinjaを使用していない環境のため。 |
参考資料


コメント